
はじめに
こんにちは, 基盤開発チームの奥山(okue)です.
High Link では, BigQuery を活用してデータの分析や可視化, 機械学習への活用を行っています.
アプリケーション DB の BigQuery へ転送には, AWS ECS Fargate + Embulk という構成でバッチ処理を実行していましたが, いくつか運用上の問題点がありました.
本記事では, BigQuery へDBのデータを転送するバッチ処理を, AWS Step Functions + AWS ECS Fargate + Embulk で実装し改善した話をします.
改善前の構成と問題点
構成
改善前のバッチ処理は下図のような構成でした. AWS RDS MySQL には 60個以上のテーブルがありますが, それらを BigQuery へ転送する処理を1つの ECS Task で実行していました. また, 定期実行は, ECS のスケジューリング機能によって行っていました.
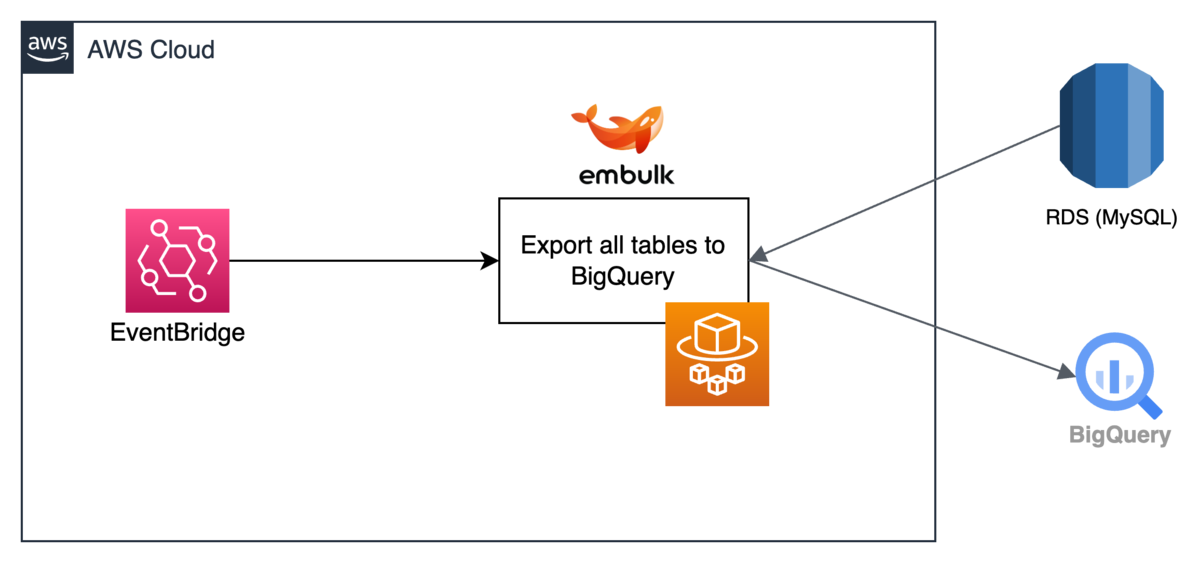
問題点
改善前のバッチ処理には, 以下のような運用上の問題点がありました.
- バッチ処理の成功・失敗の通知がされてない (MySQL のスキーマを変更で, Embulk の処理が失敗しているにも関わらず, 気づけていないことがあった)
- バッチ処理が失敗しても, どのテーブルで失敗したか分かりにくい (1つの ECS Task で全てのテーブルに対して処理をしているので, CloudWatch Logs で探しにくい)
- 特定のテーブルに絞ってリトライ処理することが難しい
このバッチ処理は, 一年以上前に構築されたもので, 当時は BigQuery へ転送するバッチ処理を早急に構築する必要があり, 細かい点を作り込むことができませんでした.
サービスや会社のフェーズによって, 必要な要件や掛けられる工数が変わるのは, 成長中のサービスならではです.
改善の要件
モニタリングやリトライと言った先述の問題点を踏まえて, 以下3点を要件として, バッチ処理の実装方法を考えました.
- 失敗時のリトライ処理や特定のテーブルに対するオンデマンド実行が容易
- バッチ処理の成功・失敗が Slack に通知される
- 各テーブルの処理時間が確認できる
実装方法の検討
実装方法としては, 主に次の3案を考えました.
- ECS Task (現状からあまり変更しない)
- Embulk を実行するスクリプトを改修する
- AWS もしくは GCP のマネージド AirFlow
- テーブル毎に Embulk 処理を実行する
- AWS Step Functions
- テーブル毎に Embulk 処理を実行する
以下は, 3案をいくつかの観点で比較した表です.

総合的に見て, Error handling, Logging, Metrics, Retry でも問題なさそうな Step Functions を用いて実装することに決定しました. マネージド AirFlowもとてもよさそうだったのですが, 金銭コストとのバランスで採用しませんでした.
Step Functions を用いた Embulk バッチ処理の実装
この章では, 実際に実装したバッチ処理について紹介していきます.
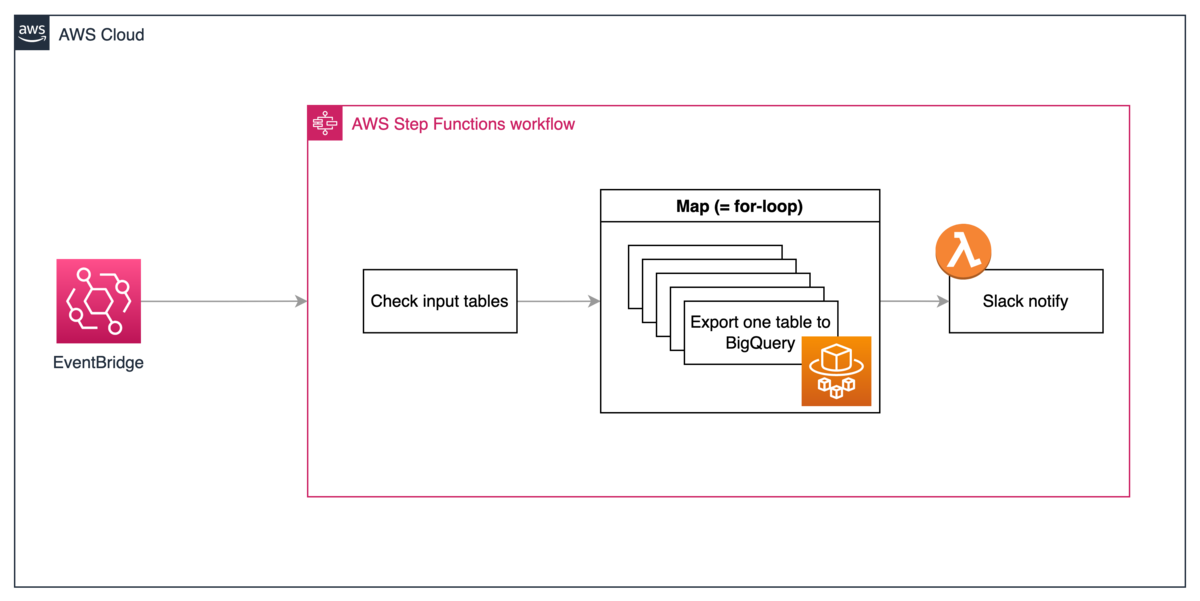
概要図
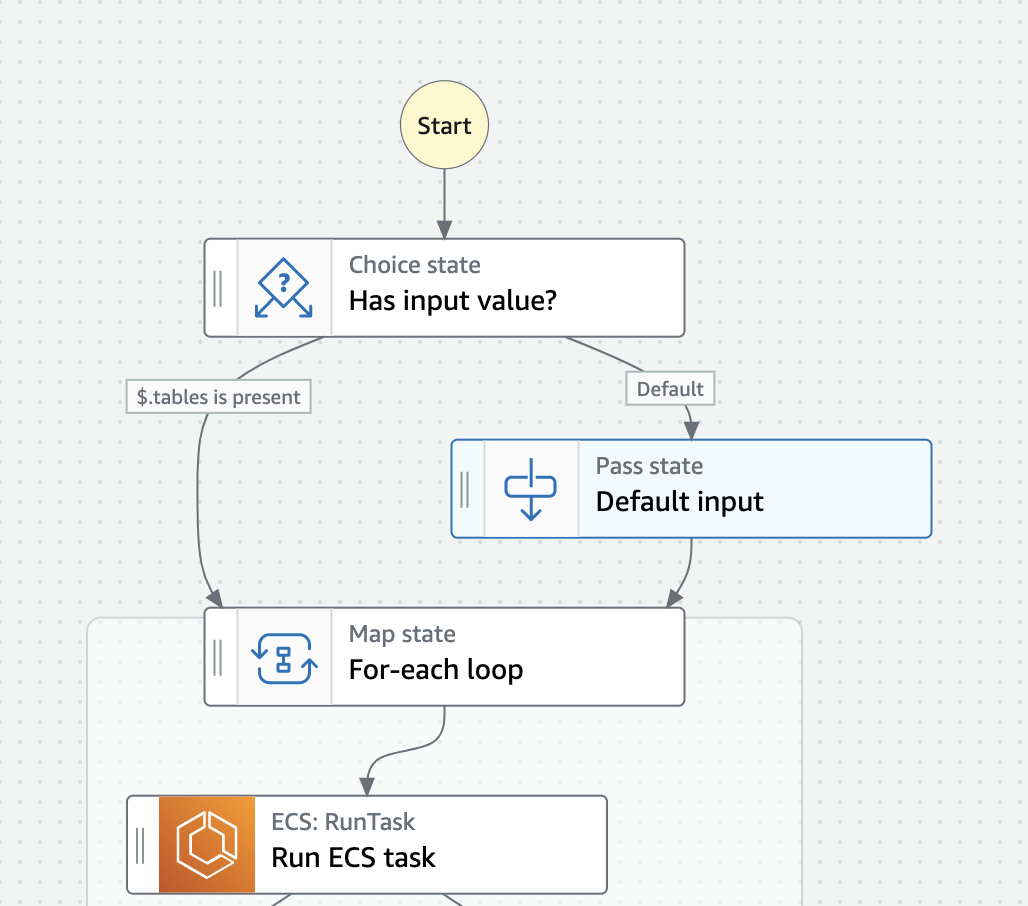
全体としては, 下図のようになりました. Step Functions には以下の3つのことをさせています.
- 入力チェック. 入力がなければ全てのテーブルを対象として, Embulk 処理を実行するように, Map (≒ for-loop) の input 値を調整.
- Map によって, ECS task を各テーブルに対して実行. ECS Task のやること自体は, 改善前から変更はしていません.
- Map の出力を Lambda で集計して, 処理結果を Slack 通知する.
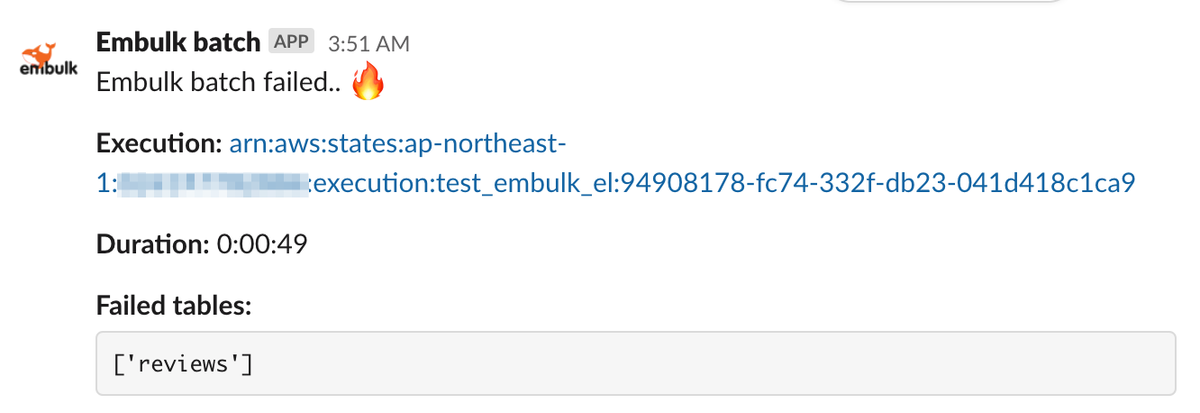
Slack 通知内容
Slack 通知は, Lambda で行っていて, 成功・失敗それぞれ下のようなメッセージを送っています.
- 実行結果
- 実行時間
- Step Functions 実行へのリンク
- (失敗の場合) 失敗したテーブル名の一覧

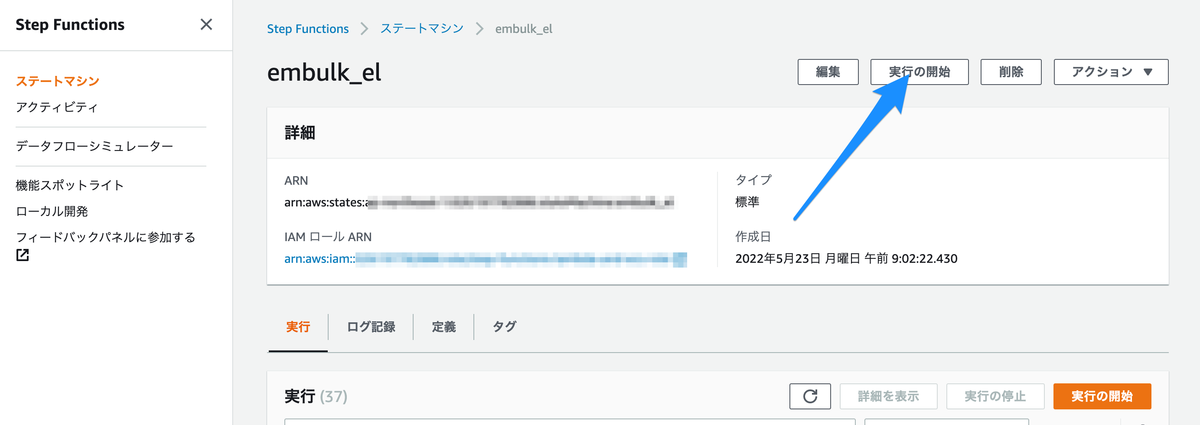
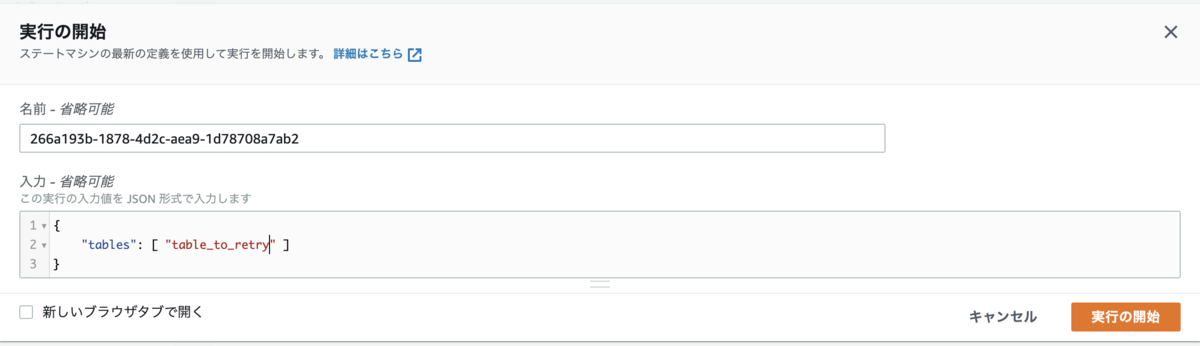
オンデマンド実行
Step Functions のページから, “実行の開始” を押して, 処理したいテーブルを入力に与えれば, 特定のテーブルに限定してオンデマンド実行できます.
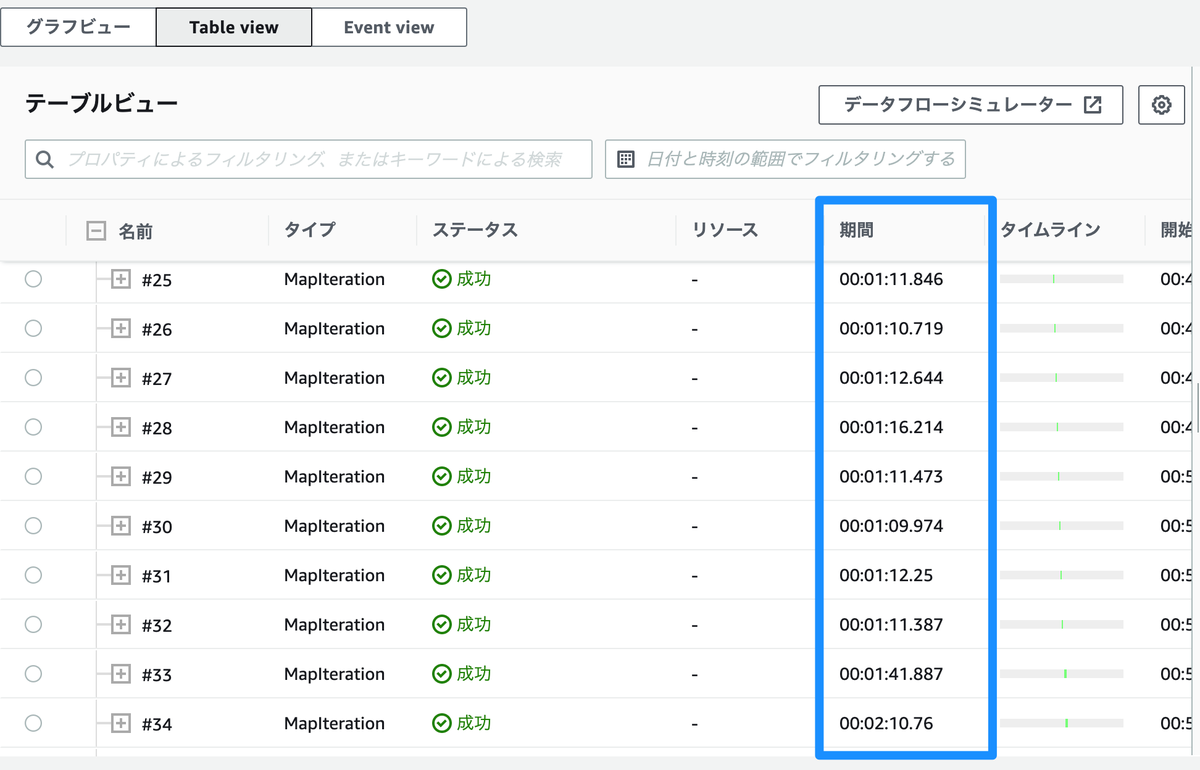
各テーブルでの処理時間の確認
Step Functions の実行結果の Table view から確認できます.
Step Functions 定義の工夫点
ここからは, Step Functions でバッチ処理を実装していった上での工夫点をいくつか紹介します.
本番用, 開発用の設定の管理の仕方
Step Functions では, ワークフロー定義を JSON もしくは YAML で管理できます.
当然ですが, RDS, BigQuery, Slack 通知先 などは本番と開発環境で異なります. かといって, 本番と開発用の JSON 定義を完全に別のファイルにしてしまうと管理が面倒になります.
なので, 以下のような簡易的なテンプレートを用意しました. ECS cluster, VPC security groups 等, 環境によって異なる部分はスクリプトで置換します.
{ ... "For-each loop": { "Type": "Map", "Iterator": { "StartAt": "Run ECS task", "States": { "Run ECS task": { "Type": "Task", "Resource": "arn:aws:states:::ecs:runTask.waitForTaskToken", "Parameters": { "LaunchType": "FARGATE", "Cluster": "arn:aws:ecs:...:...:cluster/__ECS_CLUSTER__", "TaskDefinition": "arn:aws:ecs:...:...:task-definition/__ECS_TASK_DEF__", "NetworkConfiguration": { "AwsvpcConfiguration": { "AssignPublicIp": "DISABLED", "SecurityGroups": "__VPC_SECURITY_GROUP__", "Subnets": "__VPC_SUBNETS__" } }, ... }
それぞれの環境での変数は別ファイルで下のように定義しています.
LAMBDA_NAME='arn:aws:lambda:...:...:function:embulk-slack-notify:$LATEST' VPC_SECURITY_GROUPS='[ "sg-00000000000000000" ]' VPC_SUBNETS='[ "subnet-00000000000000000" ]' ECS_CLUSTER='embulk-batch-cluster' ECS_TASK_DEF='embulk-batch-def:1' ...
デフォルト入力の実現
今回, テーブルを指定したオンデマンド実行を実現するために,
- 手動でオンデマンド実行する際は, 特定のテーブルに対してのみ処理を実行する
- 定期実行 (EventBridge) する際は, 全テーブルに対して処理を実行する
という挙動になるように実装しました.
つまり,
- 入力が
{ "tables": [ ... ] }という形式の時は,tables配列で指定されたテーブルに対して処理を実行する - 入力がそれ以外の場合, 全テーブルに対して処理を実行する
というように, 全テーブルをデフォルト入力とするような Step Functions が定義できればいい訳です.
デフォルト入力の実現には, 2 ステップあります.
- Step Functions に入力をチェックして, デフォルト入力を使うか決定させる
- Step Functions にデフォルト入力値を与える
1. Step Functions に入力をチェックして, デフォルト入力を使うか決定させる
Step Functions では, 実行を開始する際, 任意の入力を与えることができます.

また, 入力を読み取って, 条件分岐を行う Choice という機能があります.
数値, 文字列, タイムスタンプ等に関する単純な演算や論理演算子によって, 条件を定義できます.
And,Not,OrIsNull,IsPresentNumericEquals,NumericEqualsPath- …
StringEquals,StringEqualsPath- …
TimestampEquals,TimestampEqualsPathTimestampGreaterThan,TimestampGreaterThanPath- …
なので, 下のように定義をすることで, 入力をチェックしてデフォルト入力値を使うか使わないか分岐する Step Functions を構成できます.
{ "States": { "Has input value?": { "Type": "Choice", "Choices": [ { "Variable": "$.tables", "IsPresent": true, "Next": "For-each loop" } ], "Default": "Default input" }, "Default input": { "Type": "Pass", "Next": "For-each loop", "Result": { "tables": "__TARGET_TABLES__" } },
2. Step Functions にデフォルト入力値を与える
お気づきの通り, 上記 JSON の States.'Default Inputs'.Result.tables の値はダミーです.
先述の通り, Step Functions の定義はスクリプトで生成しています. スクリプトで定義 JSON を生成するタイミングで, 対象となるテーブルの一覧を __TARGET_TABLES__ に埋め込んであげます.
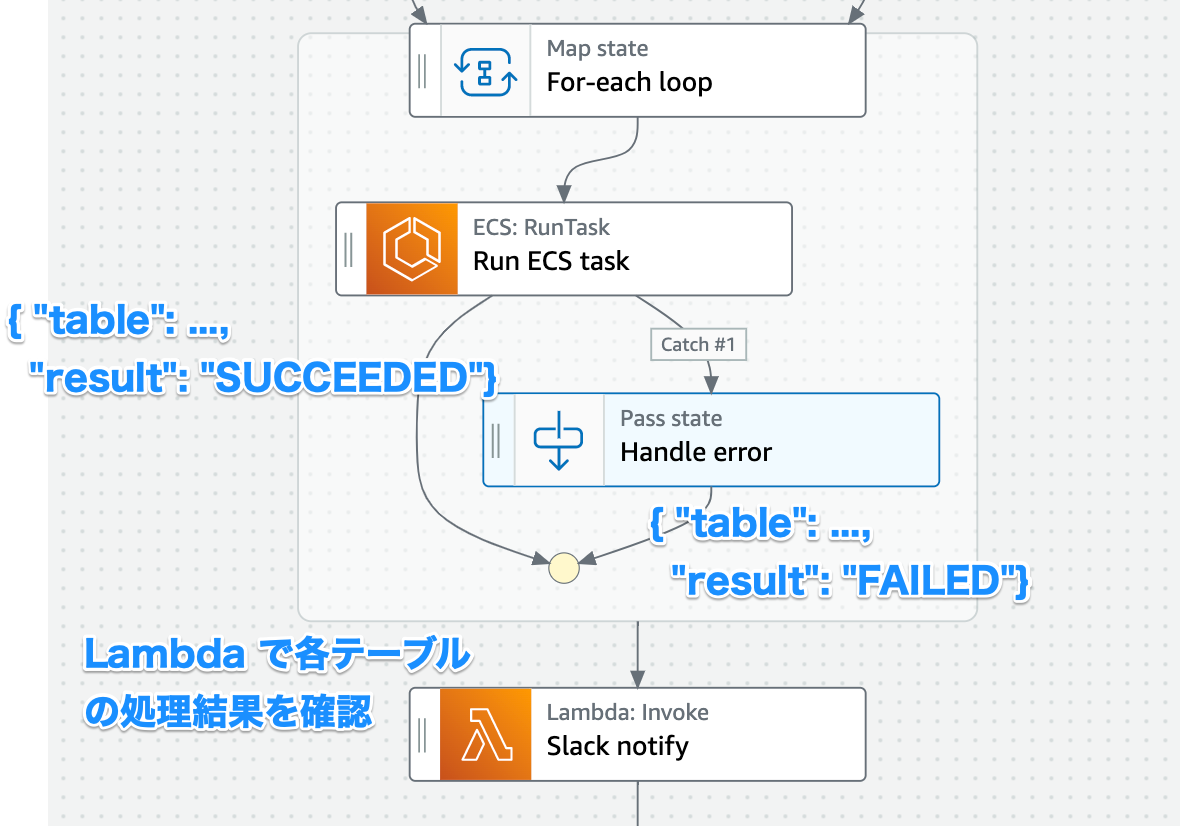
Map のエラーハンドリングと成功・失敗の集計
Map (≒ for-loop) では, loop の途中で一つでも失敗状態で終了してしまうと, 全ての処理を中断して loop をやめてしまいます.
1つのテーブルで処理が失敗したとしても, 他のテーブルの処理を完了したくないので, ECS task の失敗をちゃんと catch する必要がありました.
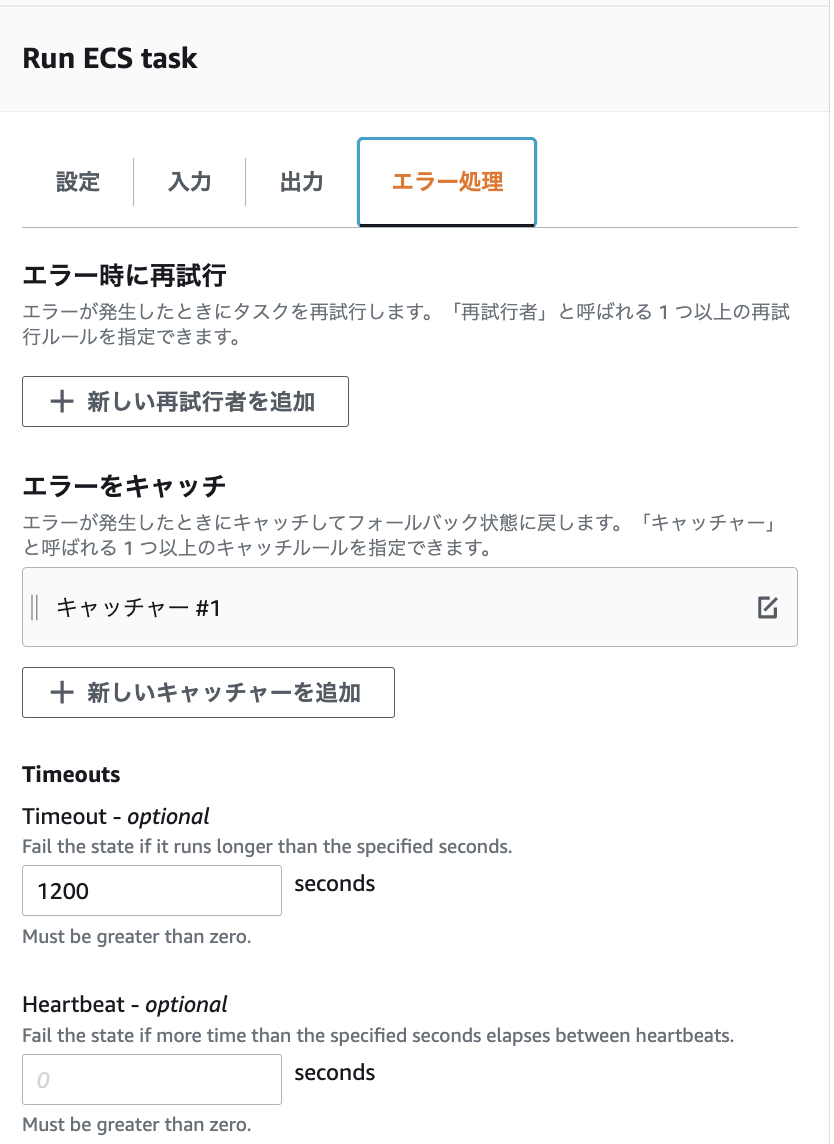
ただ, 失敗をキャッチして出力をそのまま下流に流すだけだと, その ECS task が失敗したことが Slack 通知する Lambda に伝わりません.
そこで, 成功の場合は { "result": "SUCCEEDED" }, 失敗の場合は { "result": "FAILED" } を出力に追加するようにしました. ResultSelector, ResultPath という出力を変更をする機能を利用しました.
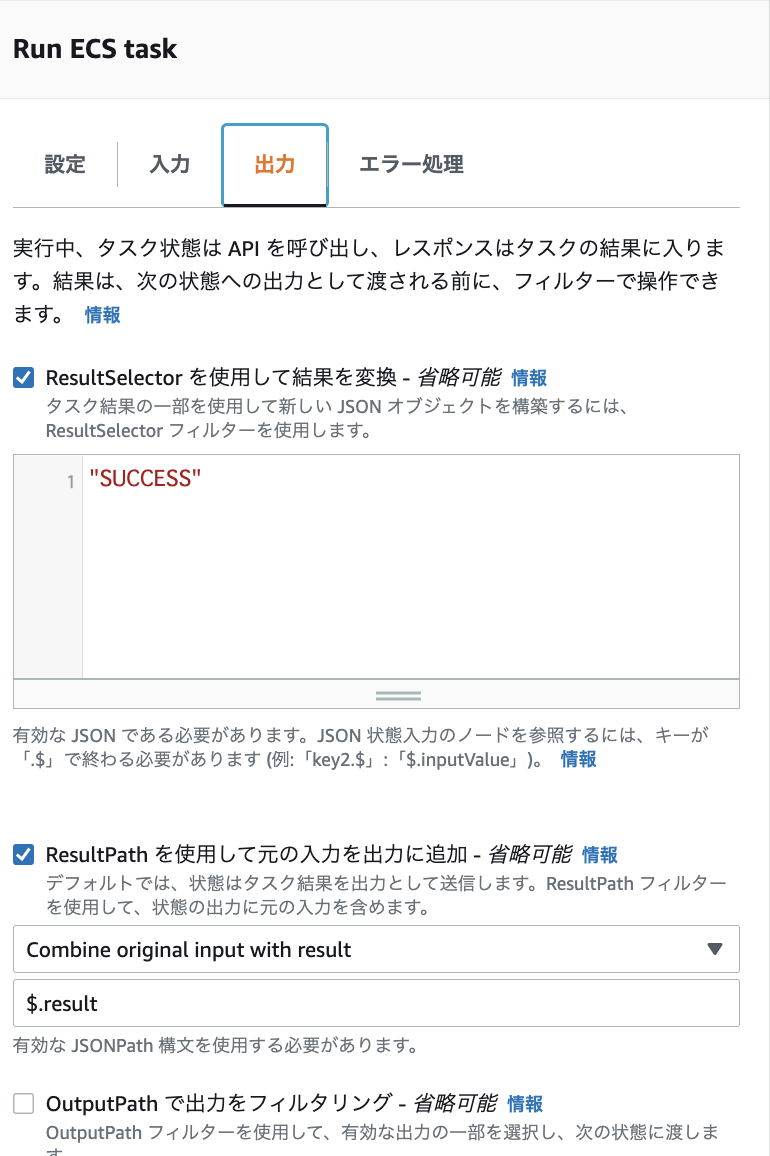
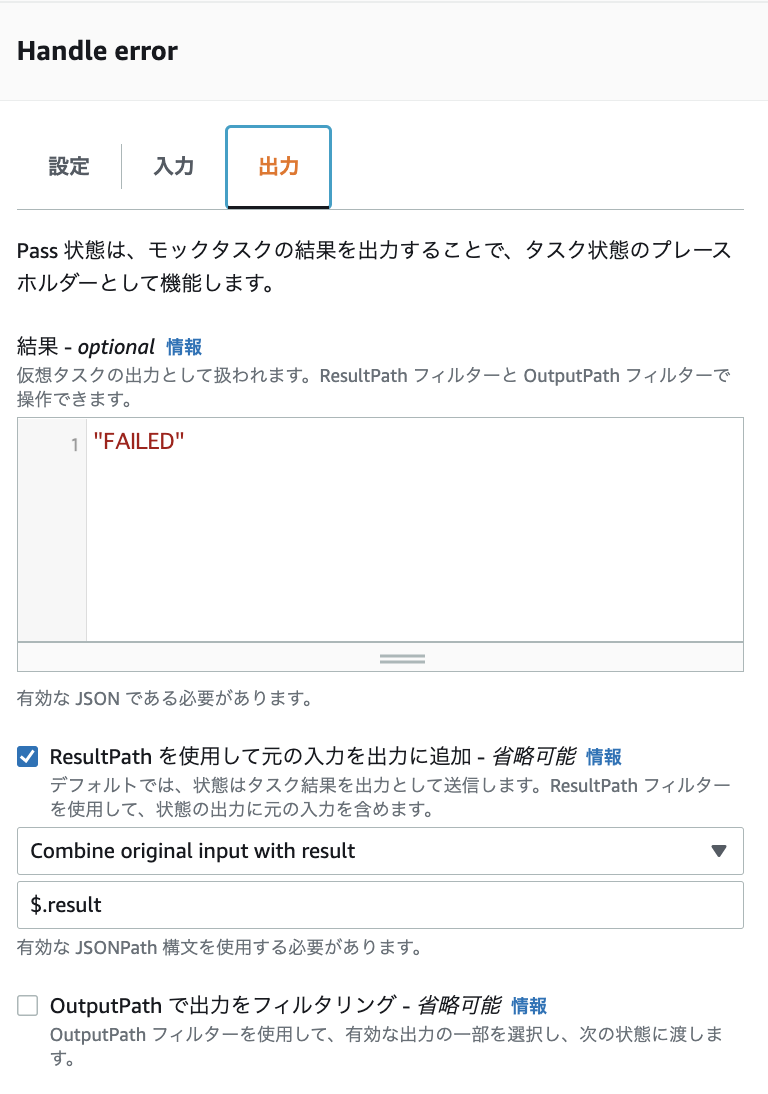
結果として, Map の出力は下図のように, テーブルの処理が成功したか失敗したか分かるようになり, Slack 通知 Lambda で処理が失敗したテーブルを検知できるようになりました.
苦労した点
- 実装方法を検討する際, AWS や GCP にワークフロー関連, バッチ処理関連のサービスが多数あるので, それぞれのユースケースの理解に時間がかかりました.
- Step Functions は便利なのですが, 概念の理解や Input, Output, ResultPath 等に慣れる必要がありました.
終わりに
Step Functions や Lambda を活用することで, リトライしやすく, 成功失敗がちゃんと通知されるバッチ処理の構築ができ, 運用上の問題が解決されました.
Step Functions は, DAG をうまく作ればリトライしやすく, 各処理にかかっている時間なども分かるので便利でした. 慣れが必要な部分もありましたが, 機会があれば今後もワークフロー処理やバッチ処理に採用したいと思いました.
High Link の基盤開発チームでは, このようにサービスの基盤に関わるシステムの開発や改善を行っています. 興味がある方はぜひカジュアルにお話をするだけでも歓迎です。詳細は下記のリンクからどうぞ!
https://herp.careers/v1/highlink/RIGo8XhyyCPQ?utm_source=hatena&utm_medium=highlinktechblog&utm_campaign=BigQuery.embulkherp.careers