
こんにちは。株式会社High Link で業務委託として働いている、データエンジニアのikki(@ikki_mz)です。
私たちデータチームでは、「データの民主化」を推進しており、全社員がデータ利活用を行えるように、dbtを用いた分析基盤の整備に取り組んでいます。
データの民主化を推進していくにあたり、テーブル・カラムの説明文は非常に重要な役割を占めます。テーブルやカラムが何を意味しているかの説明は、分析をする上ではとても重要です。
しかし、このテーブルやカラムの説明はなかなか厄介で、データベースを開発した開発エンジニアとコミュニケーションをとらないと、説明文を正確に書くことができません。
そこで私たちは、dbt・スプレッドシートを使って、テーブルやカラムの説明文の入力をするという、組織横断的なプロジェクトを実施しました。
背景と課題
dbt description について
dbtでは、yamlファイルで、テーブルやカラムの説明文(description)を記述することができます。
また、BigQuery環境では、記述したdescriptionをBigQueryコンソール上で表示することができます。クエリを書くエディタと、同じ画面内でカラムdescriptionを確認できるので、分析の際には非常に役に立つ機能だと思っています。
BigQueryでdescriptionを表示する方法は、以下の記事でも紹介しているので、良ければ参考にして下さい。
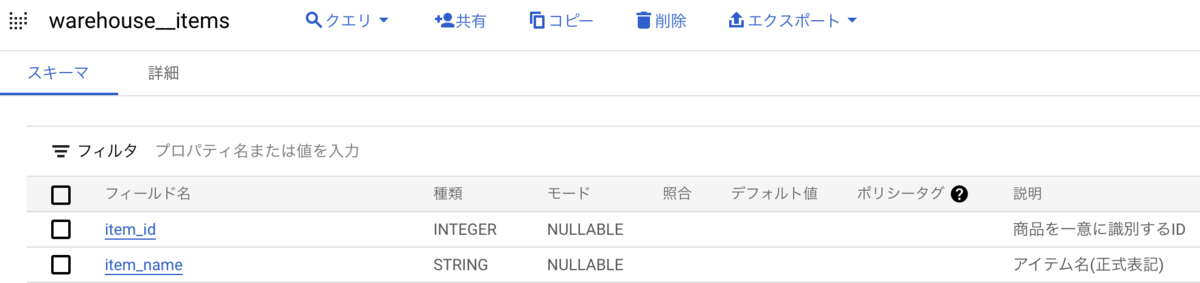
冒頭でもお話ししたように、私たちHigh Linkではデータの民主化を推進しており、誰もが分析の際にデータの情報にアクセスできるようにする必要があります。そのため、descriptionを整備することをとても重要視しています。
運用体制上の課題
上記のdescriptionを整備するにあたっての課題として、
- dbtで作業をするのはデータチームのみであるが、
- テーブル・カラムの情報は、開発エンジニアの方が詳しい
という課題が存在していました。
データチームがdescriptionを入力するとした場合、テーブルの仕様については、エンジニアチームに逐一問い合わせる必要があります。
データチームが入力を担うことで、dbtの操作まわりに関してはスムーズに業務を行えるメリットがあるものの、開発エンジニアとのコミュニケーションコストが増大し、全体としての生産性が低下してしまいます。
そこで私たちは、descriptionを入力する部分を開発エンジニアにお願いするという方針で進めることにしました。
データチーム以外のメンバーと協働しやすくするために
descriptionの入力を開発エンジニアにお願いすることになりましたが、協働にあたって以下の二点を意識しました。
- 分析でよく使われるテーブルのみに対象を絞る
- dbtの仕様をキャッチアップする必要がないように依頼をする
一点目は、description記入のROIを考え、実際の分析でよく使われているテーブルに絞って、descriptionの記入を行ったというシンプルな話です。
理想的には、全てのテーブル・全てのカラムに説明が記入されている状態を目指したいですが、開発エンジニアのリソースが潤沢ではないので、優先度の高いものからやっています。
二点目について、
dbtでdescriptionを入力する際には、dbtモデルを定義しているyamlファイルにdescriptionの記述をする必要があり、この作業をデータチーム以外にお願いする運用では、少しハードルが高いという印象がありました。
具体的には、dbtのyamlファイルの記法を覚えてもらったり、「何行目と何行目に記入してください」と指示する必要があったり、dbtの開発フローを守ってもらう必要があったり、といった様々な負担が考えられました。
極力dbtなどの操作や仕様を覚えてもらうことなく、入力作業だけを切り出してお願いしたいところです。
そこで、descriptionの入力は、誰でも馴染みのあるGoogleスプレッドシートにしてもらい、その入力結果を用いて、データチーム側でdescriptionの反映を行うことにしました。
後述するように、Googleスプレッドシートで関数を組み合わせることで、yaml形式でテキストを出力することが出来たので、このあたりの運用をかなり効率的に行うことができました。
Solution
運用フローの全体像
大まかな運用フローは以下のようになります。

テーブル・カラム情報に詳しい開発エンジニアの方に、入力用のスプレッドシートを渡して、テーブル・カラムdescriptionの入力を行ってもらいます。
そのスプレッドシートでyaml形式の自動出力を行い、データチーム側でdbt環境にコピー & マージを行うという流れになります。
①description入力フォーマットの作成
実際に使用したスプレッドシートについて簡単に触れておきたいと思います。
まず、入力用のフォーマットですが、BigQueryのINFORMATION_SCHEMAを使って、自動で生成を行えるようにします。
with column_list as ( select table_name , column_name , description from `project.dataset`.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS ) , table_description as ( select table_name , replace(option_value, '\"', '') as table_description from `project.dataset`.INFORMATION_SCHEMA.TABLE_OPTIONS where option_name = 'description' ) select column_list.table_name , table_description.table_description , column_list.column_name , column_list.description from column_list left join table_description on column_list.table_name = table_description.table_name
上記のクエリを実行することで、descriptionが入力済みのものも含めた、テーブル・カラムの一覧を出力することが可能です。

入力の際は、descriptionが空白になっているところのみ入力を行えばいいので、誰でも直感的に入力を行うことができます。
実際に、フォーマットを送っただけで余計な説明をすることなく、descriptionの記入を行ってくれました。
②yaml形式で出力
スプレッドシートに入力されたdescriptionの情報を、dbtに反映するために、yaml形式で出力する必要があります。
yamlファイルは、規則的な構造をしているので、スプレッドシートの入力データから自動で生成することが可能です。(テストを大量に盛り込んでいたりして複雑になっていると、全自動とはいかないかもしれません)
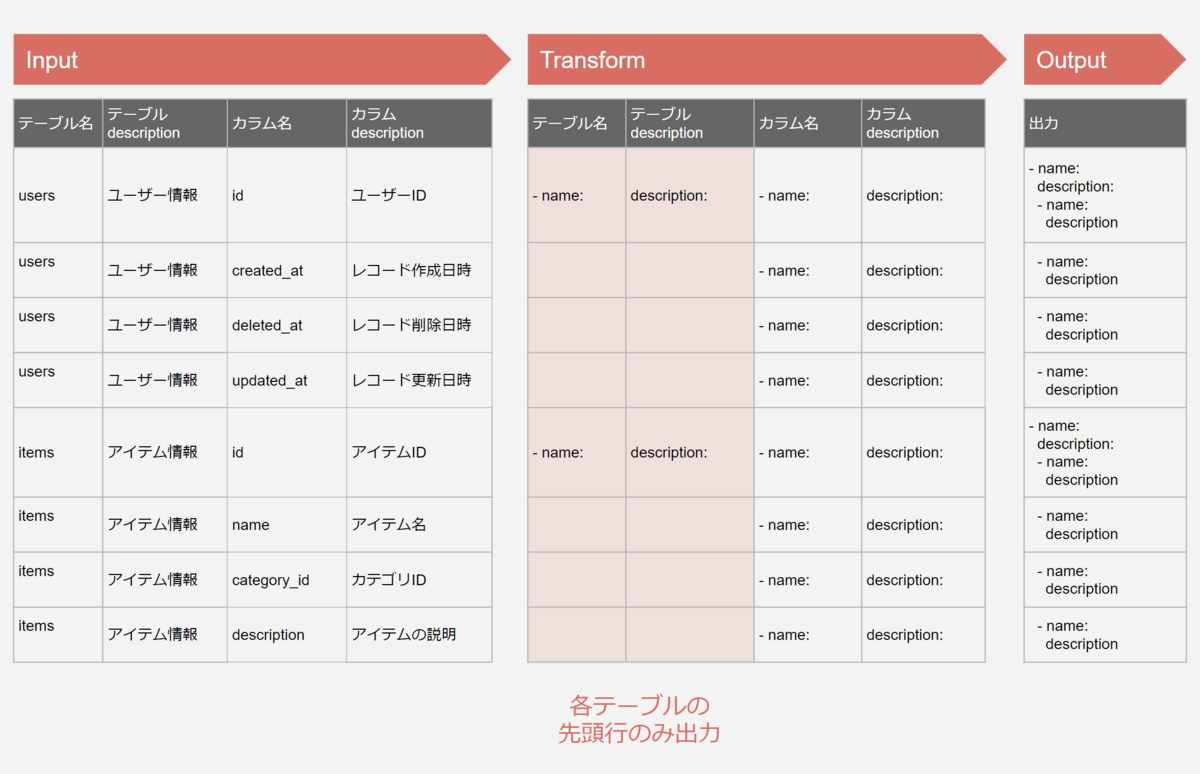
ざっくりとしたプロセスは、インプットデータを、一行ずつテキストに変換していき、それを縦に並べるというプロセスになります。

まず、テーブルについての処理です。
dbtのyamlファイルの構造的に、テーブルとカラムが親子関係にあるため、テーブルに関する記述は、スプレッドシートの先頭行のみ出力する必要があります。
これを関数にすると、以下のようになります。IF文でテーブルの先頭を判定して、出力の有無を切り替えています。(A4セルにテーブル名が入力されています)
=IF($A4<>$A3, CONCATENATE(" - name: ", A4, CHAR(10)), "")
同様のロジックで、テーブルdescriptionについても出力します。この際、テーブルdescriptionが入力されている場合のみ、出力を行うようにしています。(C4セルにテーブルdescriptionが入力されています)
=if(C4="", "", IF($A4<>$A3, CONCATENATE(" description: ", C4, CHAR(10)), ""))
続いて、カラムについての処理です。
カラムはテーブルのように、先頭かどうかを判定する必要はなく、素直に出力するだけでOKです。(D4セルにカラム名が入力されています)
=CONCATENATE(" - name: ", D4)
descriptionについても、テーブルの時と同様に、入力されている場合のみ出力する処理を入れています。(E4セルにカラムdescriptinが入力されています)
=if(E4="", "", CONCATENATE(CHAR(10), " description: ", E4))
最後に、これらをシンプルに連結した列を作ります。
=CONCATENATE(G4, H4, I4, J4)
この列を、上から下まで選択してコピーすれば、yaml形式の出力を得ることができます。

以上で、スプレッドシート → yamlファイルの自動化は完了です。
上記で説明した他に、テーブルのconfigや、カラムのtestなども出力されるようにしましたが、基本的に同じロジックで対応できるので説明は割愛しました。
③dbtに反映
スプレッドシートでyaml形式の出力ができるようになったので、dbtへの反映は基本的にコピペだけで完了します。
Githubで差分管理ができるので、スプレッドシートの操作ミスなどに気を遣いすぎる必要がないのも、良いところだと思っています。
Conclusion
まとめ
この記事では、データの民主化を推進するためのメタデータ整備の一環として、開発エンジニアと連携しながらテーブル・カラムのdescriptionを整備した話について紹介しました。
今回の取り組みにあたって、他チームと連携しながら進められたことや、データチームと開発エンジニア間の不必要なコミュニケーションを発生させることなくテーブル・カラムdescriptionを揃えられたことは、非常に良い成功体験となりました。
また、今後は新規テーブルが生まれたタイミングなど、再びdescriptionの入力を開発エンジニアにお願いすることになると思うので、今回の経験を活かし、運用ルールを再整備して、スムーズにdescription入力が行われる体制を整えていきたいと思います。
最後まで読んで頂きありがとうございました!
High Linkでは、全社的なデータ利活用を推進しています!
データチームだけがデータに関わるのではなく、組織横断的により使いやすいデータを整備できるように、今回の記事で紹介したメタデータの整備など、分析基盤を整備する取り組みを今後も推進していきます。
また、全社的なデータ活用を一緒に推進してくれる、アナリティクスエンジニア/データエンジニアの方を大募集しています!拡大フェーズのtoCサービスで、データ活用の伸びしろがある環境に興味がある方は、ぜひご応募下さい!
https://herp.careers/v1/highlink/HXnctF4rn4rD?utm_source=hatena&utm_medium=highlinktechblog&utm_campaign=table.column.explanation.input.use.spreadsheetherp.careers