
はじめに
こんにちは。High Linkで業務委託として働いている宮﨑(@ikki_mz)と申します。主にデータエンジニアリング領域でお手伝いをしています。
この記事では、elementaryのdbtパッケージで実装できる「異常検知テスト」を導入してみた話をしようと思います。
実際に発生した問題
先日、プロダクトにおいて、売上数値に影響を与えるような障害が発生しました。これは会社として問題であるため、予防策を講じる必要があります。
今回は、問題の原因がデータ基盤側にあるわけではありません。しかし、データチームで議論した結果、データ基盤側でもモニタリングできる体制を構築できると良いのではという話になりました。また、今回のようなプロダクト側の異常は、ある指標が異常に大きくなっていないかをモニタリングしておくことで検出できるだろうと考えました。
異常検知のやり方について調査を実施したところ、elementaryのanomaly detection tests(異常検知テスト)というものが使えそうだということで、今回はそれを使って実装してみました。
elementaryの異常検知テストの概要
elementaryの異常検知テストについて簡単に説明します。
特定のデータに対して、メトリクス(レコード数、NULLの割合、平均値など)を監視し、最近の値が過去の傾向から大きくずれていないかを検出してくれるテストです。
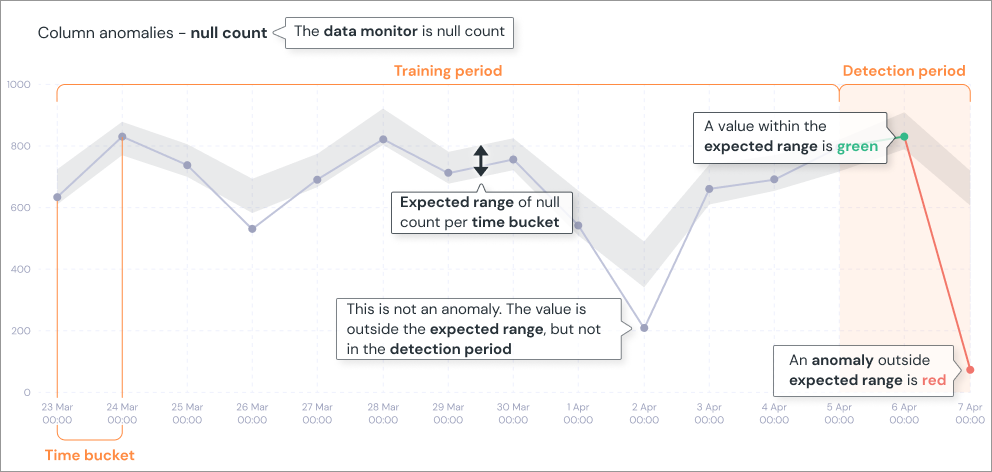
例えば、通常時にレコード数が1,000件ぐらいのデータが、急に100件になった場合に、データが欠損しているのではないかという検出を行うことができます。また、レコード数だけではなく、売上が毎日100万円前後なのに、急に200万円の日があった際にも検出することもできます。
elementaryはdbtパッケージとして提供されていて、dbtテストの一種として異常検知テストを実装することができます。具体的には、yamlに以下のような記述をすることで実装できます。
# nullの件数、平均値の異常検知テストの実装例 models: - name: this_is_a_model tests: - elementary.column_anomalies: column_anomalies: - null_count - average
yamlに数行記述をするだけで、異常検知テストがお手軽に実装できるため、非常に便利な機能だと思います。
実装時に考慮したポイント
異常検知テストは、基本的にyamlに記述するだけで簡単に実装することが可能ですが、いくつか考慮が必要だったポイントがあったので、イメージを掴んでもらうために細かく説明したいと思います。
time_bucket:日ごとにテストを行う
異常検知テストにtime_bucketというプロパティがあります。これは、どの日付粒度でテストを行うのかを設定するプロパティになります。例えば、日毎に指標を見るのか、月毎に見るのか、というように状況に応じて使い分けることができます。
最初の要件では、「月ごとの指標を見て、異常値になっていたら通知する」というものだったので、time_bucketにmonthを指定して、月ごとに異常値の検出を行おうとしていました。
しかし、当たり前の話ではあるのですが、今日を含む最新月の集計結果は、その月の間は常に変化し続けることになります。すると、月の上旬は「先月に比べて少ない」という判定がされてしまい、異常値とみなされることになってしまいます。
また、仮に最新月が異常に高い数値であったとしても、それに気づくのはその月の後半になってしまいます。月の後半になるまでは、少ない日数で集計されているため、前月の数値を超えるのに時間がかかってしまうためです。
この問題に対して、detection_delayというプロパティを使用して最新データをテストから除外することは可能です。ただし、これでは異常値の検出が1ヶ月後になってしまい、今回の「異常に早く気づけるようにしたい」という要件には反しています。
そこで、シンプルな解決策として、time_bucketにdayを指定して、「日ごとの指標」に対して異常検知テストを実装することになりました。
where_expression:月末を除く
日ごとに異常検知を行うことになると、今度は別の問題が発生しました。
High Linkが運営する「カラリア 香りの定期便」は香りアイテム(香水やルームフレグランス、バスグッズなど)を毎月お届けするサブスクサービスです。
毎月決まった日に香水が注文されるのですが、仕様上、29-31日に登録したユーザーは次月以降28日が注文日になります。
この仕様により、
- 28日の数値は、29-31日登録ユーザー分のデータを含むため他の日より数値が大きい
- 29-31日の数値は、データが存在しないため0となる
ということが起きてしまいます。
これは異常検知の際に、異常値として認識され得るため非常に厄介です。
これを適切に処理するために、where_expressionというプロパティで、「28日以降のデータを異常検知テストの対象から外す」という対応をしました。具体的には、以下のようなSQLを指定することができます。
where_expression: "extract(day from ordered_date) < 28"
このように設定することにより、1-27日のデータに対して、dailyで異常検知テストを実施することが可能になりました。
今回の使い方以外にも、whereでテスト対象のデータを絞り込むことができるので、状況に合わせて、適切なデータに対してテストが実行されるようにすることがオススメです。
テスト結果をUIで見る
実装したテストの結果は、elementaryのUIで確認することができます。
各日付における指標の値が緑色の折れ線グラフが示されており、その上下に正常値の範囲が薄いグレーで示されています。この正常範囲から外れると、異常値とみなされてテストがエラーになるという挙動になっています。
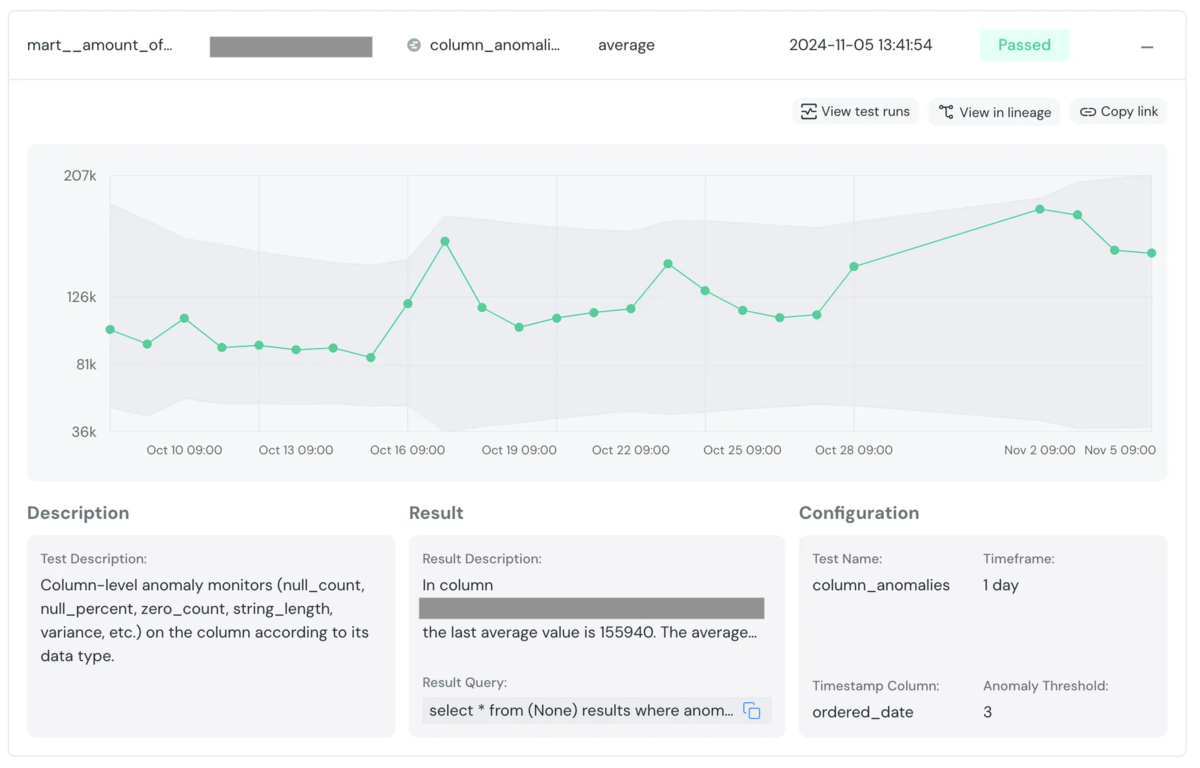
テストを実装するだけで、この見やすいUIが見られるようになるので、指標をモニタリングしたいケースではとても便利だと感じました。
実例:異常検知エラーが発生
この異常検知テストを実装して数日しか足っていない頃、早速この異常検知テストがエラーになるという事象が発生しました。
UIを見ても、直近の数値から2倍近く跳ね上がっていることが分かります。正常範囲を大きく超える値となっておりエラーになっています。
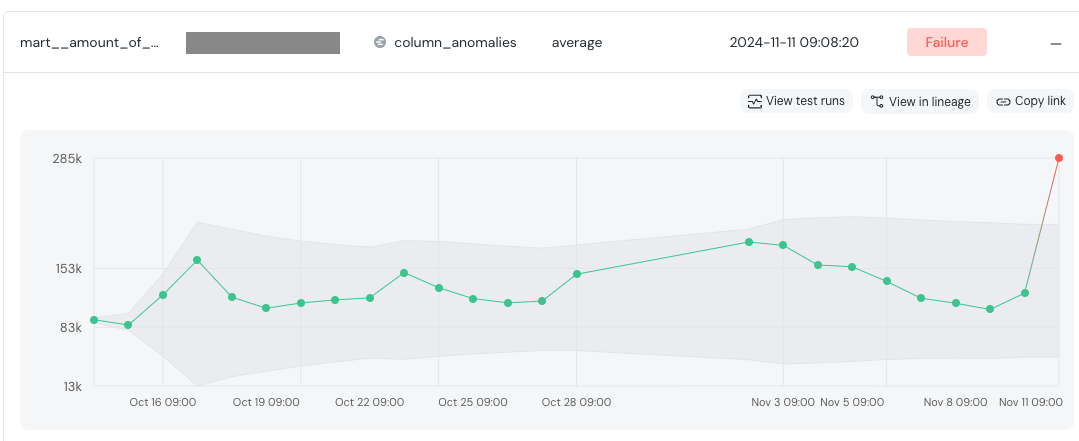
このエラーの通知をきっかけに、データチームから開発側に問い合わせを行いました。もしかすると、前回の障害時のように、正しくない状態になっているかもしれないからです。
問い合わせた結果、プロダクト側の障害などではなく、一時的なキャンペーンによって指標が瞬間的に増加しているだけの正常な挙動だということが分かりました。
このように、少しでもデータに違和感が生じたときに、関係者とコミュニケーションを取り、データの品質を担保する動きが取れたという点で、異常検知テストを実装することの価値は大きいと感じました。
今回の異常検知テストを実装していなかったとしたら、数値に違和感が生じたときに気づくことはできなかったと思います。データというのは非常にセンシティブなもので、少し問題が発生しただけで、誤った意思決定を生んでしまうリスクもあります。そのために、データ品質を担保する取り組みは今後も継続していきたいと思いました。
yamlで簡単に実装できるので、今回実装した指標以外に、他の指標でもどんどん異常検知テストを実装していこうと考えています。
おわりに
今回の記事では、elementaryで異常検知テストを導入した話と、導入した結果、異常検知テストをきっかけにデータ品質を確認できるようなコミュニケーションが生まれた、という話を書きました。
データ品質が重要というのは広く認知されていることかと思いますが、純粋なdbtのtestだけでは対応できないデータ品質の問題は多いと思います。今回はelementaryのパッケージを使ったtestを試すことができて、今後の選択肢の幅が広がりました。
yamlで簡単に実装することができるので、ぜひ皆さんも異常検知テストを使ってみてください。
High Linkデータチームでは、データ基盤構築やデータ分析を通じて、ともに事業に貢献をしていくメンバーを募集しています!
▼データチームについてはこちら